 | Dr Kurt Pflughoeft Kurt has been with Market Probe since 1999 and oversees the corporate marketing science and data mining division. He leads an experienced team of senior statisticians at Market Probe. Kurt’s team ensures that the company can provide actionable information and recommend strategic initiatives for its global clients. Read the full biography here. | Using the Random Forests1 Technique to Expand Key Driver Analysis deriving importance for interval and non-interval data By Dr Kurt Pflughoeft - 3rd June, 2010
Key driver analysis is often used in market research to derive the importance of attributes as measured via rating scale questions. Derived importance methods range from simple bivariate correlations to more sophisticated multivariate techniques such as regression2. However, many key driver techniques are limited to the use of interval-scaled data where the concept of distance exists within the ratings. Deriving importance for other data types, such as categorical, may require different approaches. One technique which works well with classification levels of customer loyalty is decision trees. From a single decision tree, the analyst can derive importance scores and get a visual representation of the classification process. A hypothetical example of a decision tree used to determine the client’s level of advocacy is shown in Figure 1. In this tree, customers who experienced neither long lines nor account balance errors are more likely to be Loyal (75%) than Non-Loyal (25%). A simple way to ascertain attribute importance for this tree is to assign more importance to attributes which appear near the top such as “long lines”.
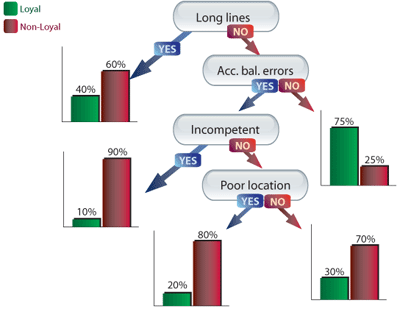
Figure 1 – Loyalty Classification Tree
One criticism of decision trees is that they tend to over-train on the data set, making the trees “brittle.” Brittle trees imply that slight changes to the data set could lead to a massive restructuring of the tree, i.e. pruning and grafting of branches. For key driver analysis, this would imply that the importance scores attained from a single tree are not stable.
Researchers have grappled with this issue and introduced specific enhancements such as bagging. Bagging utilizes a general approach named Bootstrap AGGregatING. The basic idea behind bootstrapping methods is that many other slightly-altered samples can be derived from the original sample. Table 1 identifies the original sample of five observations under the leftmost column and the slightly altered bootstrap samples labeled Boot1 through Boot3 in the remaining columns. These bootstrap samples were created by using random sampling with replacement from the original sample3. For example, in the Boot3 sample, all of the original observations happen to be randomly selected except the value 7. Instead, the random sampling procedure selected the value 11 twice.
| xi |
Boot1 |
Boot2 |
Boot3 |
| 2 |
2 |
5 |
2 |
| 5 |
2 |
5 |
5 |
| 7 |
7 |
11 |
11 |
| 11 |
11 |
15 |
11 |
| 15 |
15 |
15 |
15 |
Table 1 – Original and Bootstrap Samples
Many algorithms have been developed using bootstrap samples, including the estimation of standard errors. Bootstrap methods can be used to determine results for difficult problems especially where closed form solutions may not be available4. In fact, Random Forests usually implements bootstrap samples and other important enhancements which help overcome problems associated with a tree’s brittleness.
Random Forests creates a decision tree for each bootstrap sample and “aggregates” these trees to determine classification and attribute importance. These forests usually lead to superior performance (out-of-bag prediction); however, the nice visualization of a single tree is lost because we are now dealing with a forest5.
To illustrate the usefulness of Random Forests, key drivers are determined for comment categories associated with a bank. Example comment categories, created from open-ended questions, would be “Wait time,” “Account Errors,” etc. One thousand trees were generated for the creation of the Random Forests; the number of trees generated can be determined by the forest’s classification error rate. The importance scores for each of the comment categories, in descending order, are shown in Table 2.
| Comment Code |
Importance Scores |
| Wait Time |
37% |
| Acct Errors |
25% |
| Follow Thru |
16% |
| Competence |
9% |
| Availability |
8% |
| Fraud |
5% |
Table 2 – Importance Scores for Comment Codes
Table 3 shows the importance scores for two decision trees derived from the bootstrap sample used for Random Forests. One column represents the tree that had the lowest classification error rate while the other column represents the tree that had the highest error rate. The differences in the importance scores between these two trees are one indication of brittleness, i.e. instability in importance scores.
| Comment Code |
Importance Scores |
| Highest Error Tree |
Lowest Error Tree |
| Wait Time |
44% |
39% |
| Acct Errors |
13% |
27% |
| Follow Thru |
21% |
16% |
| Competence |
12% |
7% |
| Availability |
1% |
7% |
| Fraud |
8% |
4% |
Table 3 - Importance Scores for Two Bootstrap Classification Trees
Although key driver analysis was performed on comment categories, this type of analysis can be performed on continuous data as well. Market Probe’s experience with Random Forests shows that the results for ratings questions are similar to advanced techniques such as Theil’s. Academic research has also shown the similarity of importance scores of Random Forests with other techniques under certain conditions6.
Triangulating importance scores from both open-ended questions and rating scale questions provides new insights for clients. Although a sound survey should address many of the issues noted in comments, comments invariably alert the researcher to other issues which may be emerging. Random Forests can use information from comment categories and rating questions to derive importance for all relevant issues which may impact the client’s business.

1 Random Forests(tm) is a trademark of Leo Breiman and Adele Cutler and is licensed exclusively to Salford Systems.
2 Use of regression in the presence of multicollinearity is ill-advised for explanatory purposes. See other techniques such as Kruskal’s, Theil’s, Shapley’s, Dominance Analysis and Johnson’s Epsilon.
3 A similar technique is delete-D jackknifing which uses sampling without replacement.
4 Efron, B. and Tibshirani, R.J. (1993) An Introduction to the Bootstrap. New York: Chapman & Hall.
5 Production rules can be created for a Random Forest through packages such as RuleFit.
6 Grömping, U. (2009) Variable Importance Assessment in Regression: Linear Regression versus Random Forest. The American Statistician, 63, 314.
Kurt Pflughoeft
Comments on this article
Want to share your thoughts...?
NOTE: Please note that this board is moderated, and comments are published at the discretion of the site owner.
|
